|
|
|
| Objective |
| EANC 3.0 |
| Composition |
| Annotation |
| Transliteration |
| Software |
| EANC Team |
| Gallery |
| Armenian Texts Online |
| Research Program |
| Contact us |
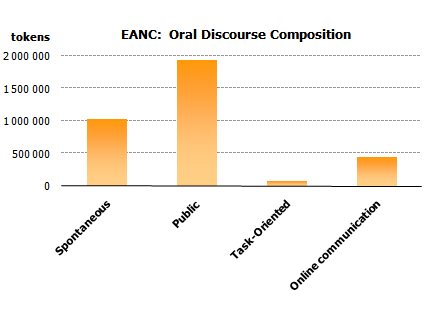
As of March 2009, oral discourse in EANC includes over 3 million tokens with the following distribution:
| Oral Discourse |
Tokens |
% EANC |
| Spontaneous | 1 029 646 | 0,9% |
| Public | 1 933 899 | 1,8% |
| Task-Oriented | 70 010 | 0,06% |
| Online communication | 442 399 | 0,4% |
| Total Oral Discourse |
3 475 954 |
3,2% |
Oral discourse in EANC is presented by the Yerevan standard. Relying on the Yerevan standard is justified by the fact that it is the closest spoken dialect to Standard Eastern Armenian. Historically, the Yerevan (Araratian) dialect served as a spoken prototype for the Eastern Armenian literary tradition.
The entire EANC oral discourse corpus has been compiled by the EANC team. Raw video and audio data were recorded in mpeg/wav format and subsequently transcribed. A written permission to record respondents was obtained whenever possible. For ethical reasons, names and other identity markers in the oral spontaneous subcorpus have been replaced by placeholders (randomly chosen capital letters).
A small subcorpus of online communication (internet forum posts, blogs, etc.; 442,399 tokens) included in the oral subcorpus is comprised of texts linguistically intermediate between oral and written discourse: see the relevant checkbox under Oral in the Subcorpus Selection window.
Recording
Oral Public Discourse (currently at 1,9 million tokens) was compiled in video format. It includes various recordings of public debates, talk shows, interviews, etc. broadcast by Armenian TV stations such as PTV1, PTV2, Kentron, Yerkir media, Armenia TV, TV5, among others.
Oral Spontaneous Discourse and Oral Task-Oriented Discourse were recorded as audio. The respondents were speakers of the Yerevan standard and were selected in an attempt to obtain a balanced mix of age, gender, and social status. Oral Spontaneous Discourse (over 1 mln tokens) includes spontaneous dialogues and diverse narratives. Oral Task-Oriented Discourse (over 65,000 tokens) covers:
- Favorite films. Currently consists of 18 narratives (respondents describing their favorite movie) containing 33,000 tokens.
- Image-based narratives. Part of a four-language (Armenian, Russian, Italian, English) project by Victoria Khurshudian, in which respondents were asked to tell a story based on a fixed series of images. The Armenian part includes 40 task-oriented oral narratives (32,500 tokens). 10 respondents between the ages of 20 and 30 were interviewed. The recordings were made in Yerevan in 2003-2004.
Transcription
Once the raw audio/video data has been obtained, it is transcribed in a "shallow" transcription, which follows traditional Armenian orthography and punctuation, with the addition of several special tags: == for falsestarts, = for fragmented words, <> for ambiguous words, ## for comments. A detailed discourse transcription used in representations of some other oral corpora may be implemented in the future. Three audio samples supplemented by "shallow" transcription are provided for your reference.A sample of Goris dialect is provided as a reference point to Armenian dialectal variety. Recording and processing
| Type | Description | MP3 sample audio | Transcript |
| Oral Public Discourse | Interview with Ervand Ghazanchyan,
Erkir Media TV |
OPD Sample | OPD Transcript |
| Oral Spontaneous Discourse | Dialogue in a shop | OSD Sample | OSD Transcript |
| Oral Task-oriented Discourse | Cartoon narrative | OTOD Sample | OTOD Transcript |
| Dialect Discourse | Goris dialect | Goris Sample | Goris Transcript |

