|
|
1. Token query
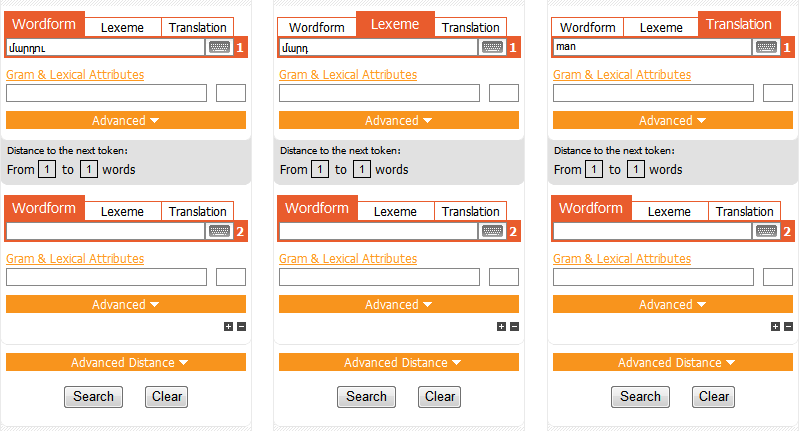
This section provides guidance on building single-token queries in EANC:
The third option (Translation tab) is to search for occurrences of lexemes by their English equivalents. In this mode, EANC will look for occurrences of tokens whose translations begin with the English word or expression (such as phrasal verb, idiom etc.) indicated in the query. In the EANC wordlist, most lexemes are associated with their English equivalents. By default, the search will only return the tokens whose primary translation matches the word in the query; if all lexical items whose translation may include a particular English equivalent are needed, the query should be preceded by a *. To look for complex meanings expressed by a combination of words, enclose the query in quotation marks (e.g. "bring up" or "*pick up").
See query example
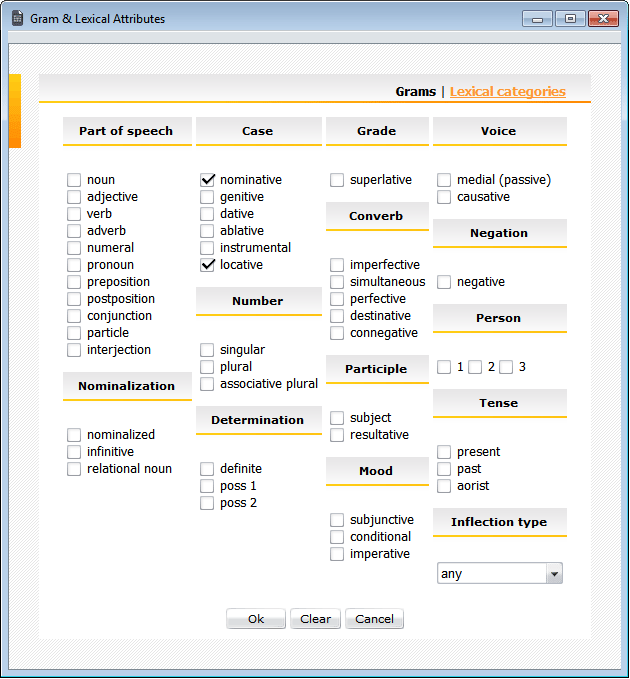
Grammatical attributes in the Gram Selection window are grouped into categories such as Part of speech, Nominalization, Case, Number, etc. Each category is visually placed in a separate area.
If you select attributes that belong to different categories, only tokens possessing all of the specified attributes will be returned. The following gram query will find all tokens tagged as both singular and definite:
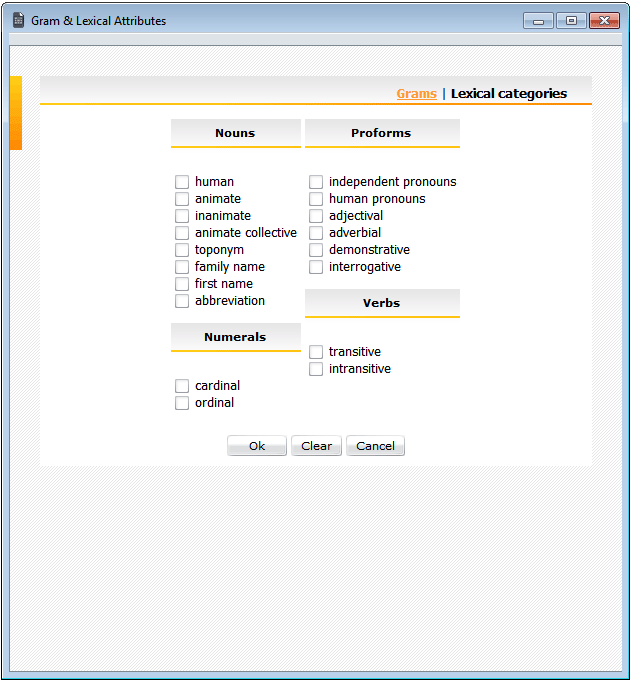
You can also restrict your search to specific semantic types of pronouns, nouns, numerals or verbs by clicking the Lexical categories tab.
If several features under the Lexical categories tab are selected by the user, they are combined in the query via logical 'or'. The only exception to this is “interrogative”, which combines with any other selection under Proforms and results in gram query lines such as ‘S,intrg’ for interrogative independent (substantive) pronouns like ով ‘who’. If you want to combine several search criteria from the two different tabs (as for example when looking for plurals of first names), check the required position(s) under one of the tabs, then go to the other tab (without clicking OK) and check the rest of the search criteria; then click OK. The sets of features selected under different tabs will be in ‘and’ relation to each other.
In the examples above the tokens returned by the queries were specified solely by their grammatical and/or lexical attributes. You can further restrict such search to the wordforms of a particular lexeme. To do this, select the grammatical attributes as before and enter a lexeme in the token query line. Such search query returns the wordforms of the specified lexeme that have the selected grammatical attributes. Thus, searching for տուն tun in singular definite yields such forms as nominative տունը tunə and տունն tunn , dative տանը tanə etc.
The Ambiguity drop-down menu allows choosing whether matches with multiple analyses are included in the query results. There are two types of ambiguity in the corpus. Grammatical ambiguity can be exemplified by the form գրել grel, which may be interpreted as either the perfective converb or the infinitive of the verb գրել grel ‘write’. An example of lexical (interlexical) ambiguity is the form հարգի hargi, which may be interpreted as the adjective ‘respectable’ or the 3rd person present subjunctive of the verb հարգել hargel ‘respect’. Setting the Ambiguity field to “disallowed” will exclude both types of ambiguity. Choosing “allow interlexical” would include results with lexical ambiguity, while rejecting the ones with grammatical ambiguity.
In the token query line, you can use logical 'OR' (|) to search for occurencies of any of several alternative wordforms or lexemes. You can also use logical 'NOT' (~) to exclude specific wordforms or lexemes.
In the gram query line, in addition to the logical 'NOT' (~) and 'OR' (|), you may also use logical 'AND' (,). Once one or more grammatical and/or lexical attributes have been selected in the Gram Selection window, a corresponding logical expression is generated automatically in the gram query line. Note that relational nouns, converbs, and participles in EANC correspond to multiple tags.
| ||||||||
 | |||||||||
 | |||||||||