|
|
5. Отображение результатов
В этом разделе описывается работа с результатами поиска в ВАНК:
5.1. Поиск
5.2. Статистика
5.3. Нулевой отклик
5.4. Тяжелые запросы
5.5. Постраничная выдача
5.6. Расширенный контекст
5.7. Лексико-морфологический разбор
5.8. Сортировка
5.9. Отображение армянских букв
5.10. Формат выдачи
5.1. Поиск
При нажатии кнопок Искать или Быстрый поиск начинается поиск вхождений, удовлетворяющих заданным поисковым критериям.
При этом на экране появляется сообщение о прогнозируемом времени поиска (для контекстных запросов – сперва по первому, потом по второму и так далее слову). Прогноз времени поиска является приблизительной оценкой. Если вы видите, что запрос «тяжелый» и займет слишком много времени, вы можете нажать на кнопку прервать.
В некоторых случаях в корпусе не находится никаких удовлетворяющих запросу вхождений. В этом случае появляется сообщение о том, почему именно вхождений может не быть (в корпусе не встречается та или иная лексема или словоформа или их сочетание, указанные грамматические признаки не сочетаются между собой и т.п.). При нулевом результате поиска проверьте также, не выбраны ли какие-то дополнительные сужающие поиск параметры в закладке Дополнительно под ссылкой Грамматика.
Если щелкнуть по ссылке Поиск в новом окне, открывается новое окно ВАНК. В каждом таком окне вы можете осуществлять запросы совершенно независимо, в том числе использовать разные подкорпуса – это позволяет сравнивать результаты поиска по двум близким, но не идентичным запросам (или, например, сравнивать употребление одной и той же конструкции в 19-м и 20-м веках и т.п. – см. пример запроса).
5.2. Статистика
В верхней части экрана отображается общая информация о запросе и полученных результатах:
- число вхождений (в случае контекстного запроса с числом контекстов, приближающимся к пороговому значению 10,000 или превышающим его – примерная оценка их общего числа в корпусе или пользовательском подкорпусе)
- число документов (в случае контекстного запроса с числом контекстов более 10,000 – примерная оценка числа документов, в которых они встречаются)
- критерии сортировки (если они были определены пользователем)
- размер подкорпуса, по которому осуществлялся поиск (в процентах от общего числа словоупотреблений в корпусе), а также количество выбранных документов

Для некоторых запросов в ВАНК содержится более 10 тыс. вхождений. По соображениям технического характера система предоставляет пользователю доступ лишь к 10 тыс. контекстов. Эти контексты равномерным образом распределены между документами ВАНК: они представляют подборку примеров, диверсифицированную по годам создания, авторам, жанрам и т.п. Если пользователь работает с подкорпусом, примеры равномерно (пропорционально размерам документов) представляют те тексты, которые вошли в подкорпус.
5.3. Нулевой отклик
В тех случаях, когда запросу пользователя не соответствует никаких контекстов, на экране появляется сообщение о вероятных причинах отсутствия отклика.
Если сообщается, что в корпусе не найден определенный элемент запроса, проверьте написание лексемы или словоформы в строке поиска. Если речь идет о поиске лексемы, не исключено, что ее нет в грамматическом словнике ВАНК. В этом случае вы можете ввести ту или иную конкретную словоформу этой лексемы в закладке форма и попробовать поискать ее вхождения как словоформы (в том числе используя * вместо окончания для поиска всех словоформ). Если нулевой отклик получен при грамматическом запросе, причина может быть в том, что в корпусе не найдено словоупотреблений, сочетающих искомые грамматические и/или лексические признаки (сюда же включаются и дополнительные параметры поиска – пунктуация, положение в предложении и т.п., заданные в закладке Дополнительно под поисковой строкой). Таким образом следует удостовериться в том, что указанные грамматические признаки совместимы между собой, а также проверить, не выбраны ли в закладке Дополнительно поисковые признаки, слишком сужающие запрос. То же сообщение появляется и в случае, когда при ручном вводе грамматической пометы или содержащего грамматические пометы логического выражения была допущена ошибка синтаксиса или написания пометы (например, “sing” вместо “sg” или “coverb” вместо “converb” или “N&loc” вместо “N, loc”). Синтаксис логических выражений описан в разделе Поиск по грамматическим признакам, а полный список помет приведен в разделе о грамматических пометах ВАНК.
Второе сообщение, которое может появиться на экране, сообщает, что не найдены вхождения, объединяющие указанные элементы запроса. Это значит, что лексема (словоформа) в корпусе встречается, но эти вхождения не отвечают заданной комбинации грамматических признаков или не удовлетворяют указанным дополнительным параметрам поиска.
В случае поиска нескольких слов может появляться сообщение о том, что искомые слова или словоформы не встречаются в одном контексте. Это значит, что каждый из одиночных запросов, из которых состоит запрос, в корпусе встречается, но не найдено контекстов, в которых эти вхождения встретились бы одновременно (с выполнением условий, наложенных пользователем на расстояние между вхождениями и/или их взаимное расположение).
5.4. Тяжелые запросы
Некоторые запросы могут приводить к длительному времени ожидания результатов. При поиске одиночных вхождений это происходит в том случае, если вы сформулировали слишком широкий запрос (запрос, которому отвечает слишком большое число словоупотреблений). Вот самые распространенные случаи тяжелых запросов:
- поиск лексемы или словоформы со звездочкой, если указаны только один или два символа (например, все словоформы, которые начинаются на *ան *an)
- такое использование логического отрицания ~, при котором запросу отвечает большое число вхождений (например, ~մարդ ~mard, то есть любая лексема, кроме մարդ mard, или ~V, то есть любая словоформа за исключением глагольных словоформ)
- поиск очень частотной граммемы без дополнительных ограничивающих поиск условий (например, запрос типа “N”, т.е. запрос на поиск имен существительных в любой форме)
При этом следует иметь в виду, что любой контекстный запрос, который включает тяжелый запрос по одиночному вхождению, будет обрабатываться так же долго, как это одиночное вхождение, даже если запрос сам по себе высокоспецифичен. Например, поиск форм лексемы խմել xmel,за которой следует лексема մոտ mot, обрабатывается моментально, причем дает только четыре результата. Если же к этому запросу добавить условие, что за մոտ mot должно следовать существительное, поиск будет осуществляться очень долго.
Если вы видите, что прогнозируемое время поиска очень велико, нажмите на кнопку прервать.
5.5. Постраничная выдача
Чтобы листать результаты, используйте ссылки Первая и Последняя или ссылки с номерами страниц в нижней части окна выдачи. По умолчанию на одной странице отображаются десять контекстов. Изменить число контекстов на странице можно в окне Настроек выдачи.
5.6. Расширенный контекст
Каждый контекст представлен в окне выдачи одним предложением (исключением является поиск, при котором областью поиска является документ – см. Дополнительные параметры поиска); слова-вхождения при этом выделены оранжевым цветом. При каждом контексте приводятся базовые библиографические характеристики (если они известны) – автор, название, год создания, для прессы также номер или дата выпуска.
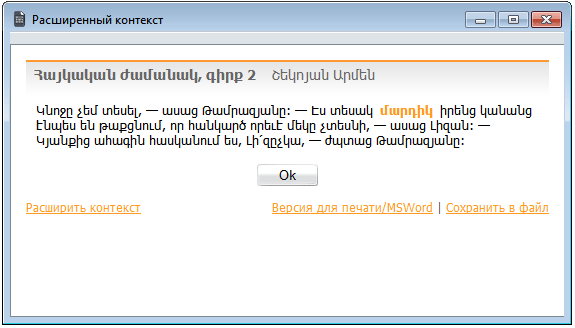
Чтобы расширить контекст найденного предложения, щелкните по ссылке Расширить контекст (в правой части строки библиографических данных).
Откроется окно расширенного контекста. По умолчанию на экран выводятся три предложения – то предложение, в котором обнаружены искомые вхождения, а также одно предложение до него и одно предложение после него. Снова щелкая по ссылке Расширить контекст, вы можете увеличивать размер контекста вплоть до девяти предложений (четыре предложения до и четыре предложения после того предложения, в котором обнаружено вхождение). Устанавливаемый по умолчанию размер расширенного контекста можно изменить, выбрав соответствующую установку в окне Настройки выдачи.
Для текстов, которые не защищены законом об авторском праве (некоторые классические произведения, пресса до 1920 г., тексты устного корпуса и др.), контекст может расширяться без ограничений.
5.7. Лексико-морфологический разбор
Если навести мышь на армянскую словоформу, во всплывающем окне отобразится ее лексико-морфологический анализ (начальная форма лексемы, ее словоклассифицирующие признаки, словоизменительные признаки словоформы, английские переводные эквиваленты - также см. Список помет ВАНК). Чтобы отключить всплывающее окно, выберите соответствующую установку в Настройках выдачи в поле Показывать грамматический разбор.

5.8. Сортировка
ВАНК позволяет осуществлять сортировку контекстов по целому ряду параметров:
- начальная форма словоформы-вхождения (лексема)
- словоформа-вхождение
- словоформа слева от словоформы-вхождения
- автор
- название
- год создания (как по возрастанию, так и по убыванию)
- жанр
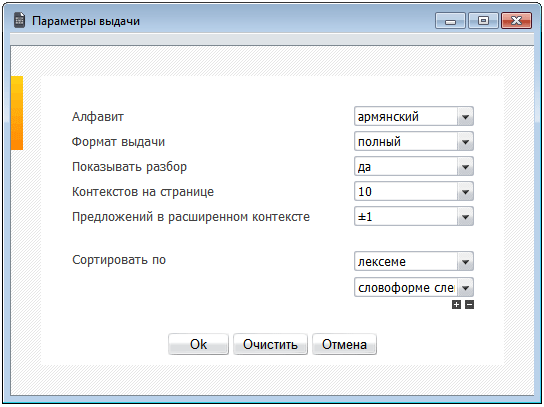
Критерий сортировки можно выбрать в окне Настройки выдачи. Сортировку можно осуществлять одновременно по нескольким критериям, например, сортировать результаты грамматического запроса сперва по лексеме, затем по ее словоформе. Чтобы добавить (удалить) критерий сортировки, щелкните по значку Плюс (Минус) под соответствующим полем.
5.9. Отображение армянских букв
Если армянские буквы отображаются на вашем компьютере некорректно, попробуйте использовать отображение армянского текста в транслитерации – для этого измените соответствующую установку в Настройках выдачи. Используемая в ВАНК транслитерация в основном следует традиции Хюбшманна-Мейе. Транслитерация используется в том числе при отображении имен авторов и названий произведений.
5.10. Формат выдачи
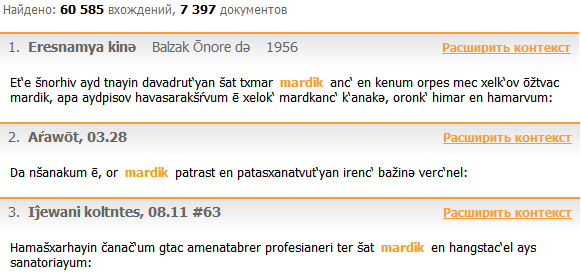
ВАНК поддерживает четыре формата отображения найденной информации:
- полный (по умолчанию): каждый контекст сопровождается базовыми библиографическими сведениями (автор, название, год создания);
- краткий: библиографические сведения приводятся только в окне расширенного контекста;
- глоссированный: этот формат предназначен в первую очередь для лингвистов-типологов и людей, изучающих армянский язык. Отображение текста близко к так называемому морфологическому глоссированию (interlinear morphological glossing), используемому в типологических публикациях и описаниях малых языков, но без разбиения на морфемы и поморфемного перевода. Для всех словоформ, за исключением словоформ, которые не разбираются парсером ВАНК, на экран в виде столбца, расположенного непосредственно под лексемой, выводится лексико-грамматический анализ, который в других типах выдачи доступен только при наведении мыши. В первой строчке столбца содержатся исходная форма и лексические признаки (например, частеречная характеристика). Во второй строке в фигурных скобках приводятся грамматические (словоизменительные) признаки словоформы (за исключением неизменяемых лексем). Если лексеме приписан перевод, он дается в третьей строчке. Если у словоформы существует несколько разборов, они отделяются друг от друга светло-серой горизонтальной чертой.

- KWIC (Key Words In Context): принятый в корпусных интернет-ресурсах способ отображения контекстов таким образом, чтобы они были визуально выровнены друг относительно друга по вхождению. Формат KWIC используется обычно вместе с сортировкой по словоформе или левой словоформе. Как и в кратком формате выдачи, библиографические данные приводятся только в окне расширенного контекста. Стрелки вправо и влево позволяют сместить "видимую часть" непосредственного контекста вхождения.

|

